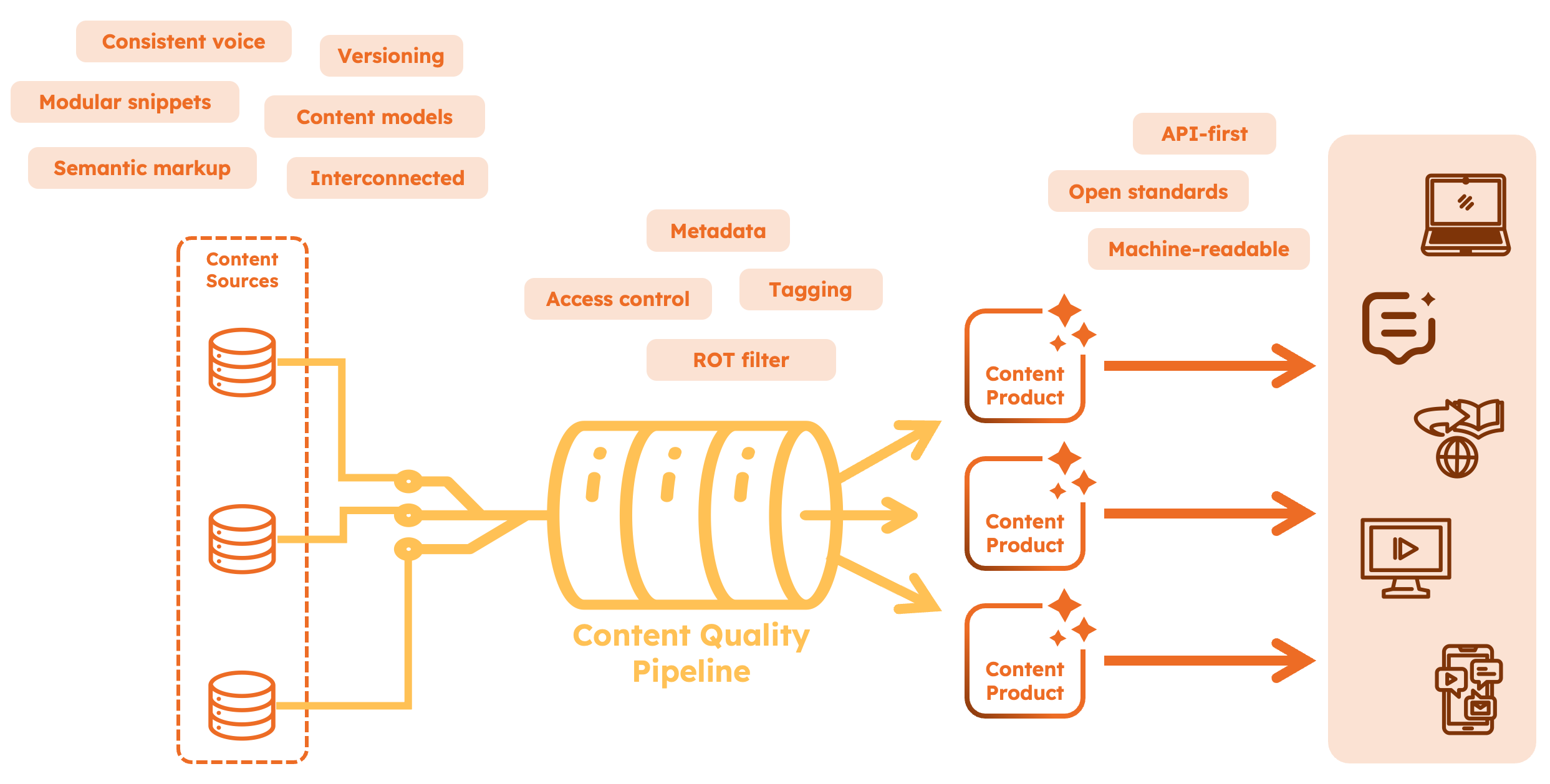
Content modeling is key
For your content to truly shine in the long-term, it needs more than just a clear headline and good SEO. It has to be organized in a way that machines can understand and use without guessing. If your content is locked in PDFs or scattered across long-form pages, AI tools may extract irrelevant text, miss context, or produce incorrect summaries.
Traditional CMSes are holding us back
Most content on the Web today is still created and published through traditional content management systems, which focus on WYSIWYG page composition. While suitable for human browsing, this structure isn't optimized for the way AI systems retrieve data.
AI tools that use methods like Retrieval Augmented Generation (RAG) rely on breaking content into chunks as part of their internal architecture. However, if content is locked in page-based formats, that chunking process is often crude, splitting text by token length or paragraph without understanding meaning.
This results in a best effort from AI systems to interpret your content, with inaccurate or vague results.
Headless CMSes facilitate modular content
Unlike page-based systems, headless CMSes use content models as their primary way of representing content: instead of big blobs of content, authors work with a structured repository of content types and interconnected entities, each having clearly defined fields like product name, description, features, compatibility, support steps and FAQs (see example in the diagram below). This structure makes it easier for AI systems to pull exactly what they need, when they need it, whether for use in a chatbot, an AI summary or a voice assistant.
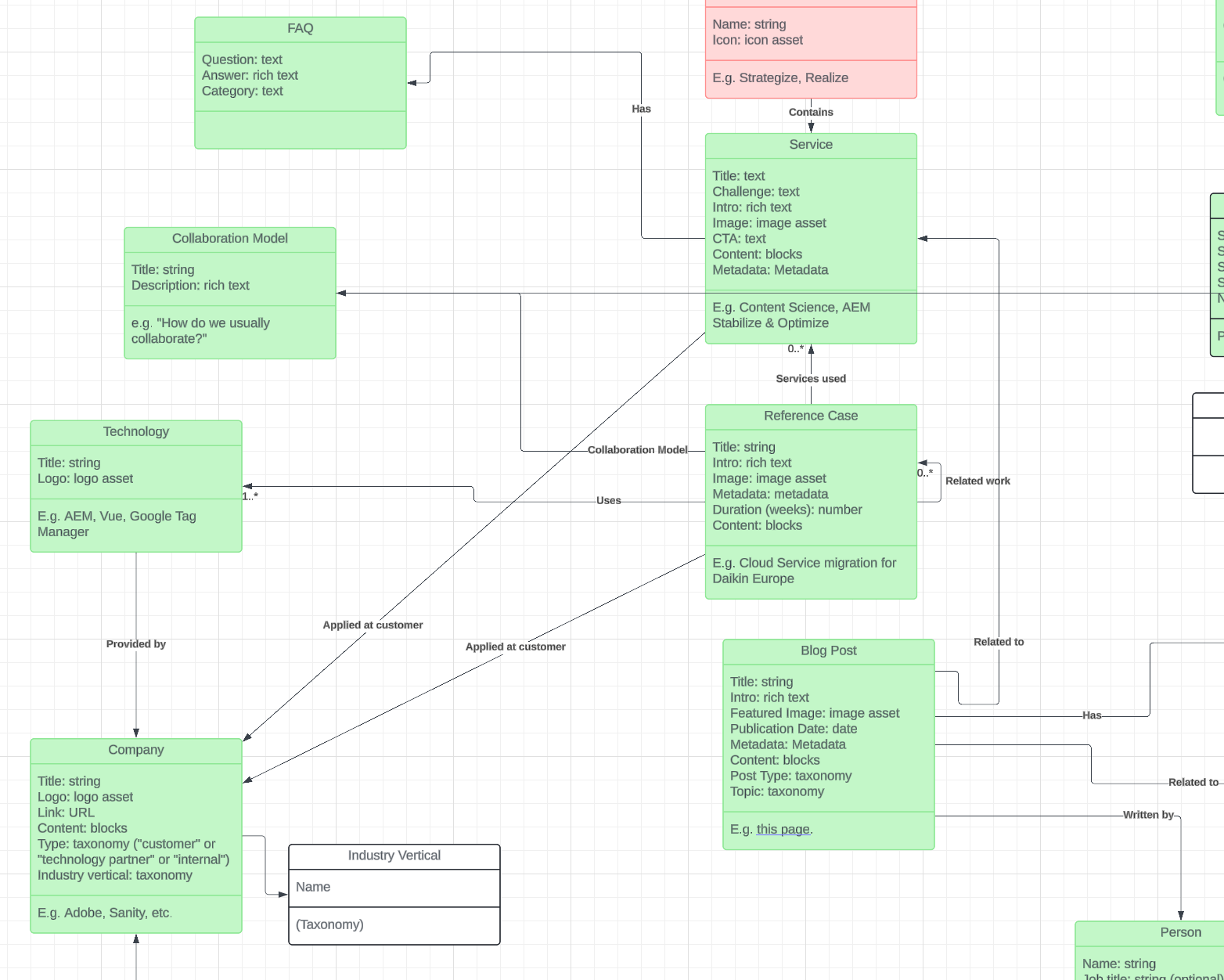
Early content model for AmeXio Fuse (as an example)
It also means your content becomes reusable across channels: the same product info can show up in a support flow, a help article, or an AI assistant, all without duplication.
Moreover, headless CMSes typically come with powerful APIs (REST or GraphQL), enabling external consumers to efficiently retrieve content.